news
MiniMax M3 Is Here — Now Available on TokenFans
MiniMax’s new flagship model with 1M-token long context, built to be a strong contender for agentic coding.
Model Scout · 2026-06-01

If you are building with AI every day, especially in coding agents, long-context workflows, tool use, and multi-step automation, M3 is a model worth paying attention to. It is not just another general chat model. MiniMax is positioning M3 as a frontier coding and agentic model with three important directions combined in one release: long context, open-weight availability, and agent-oriented performance.
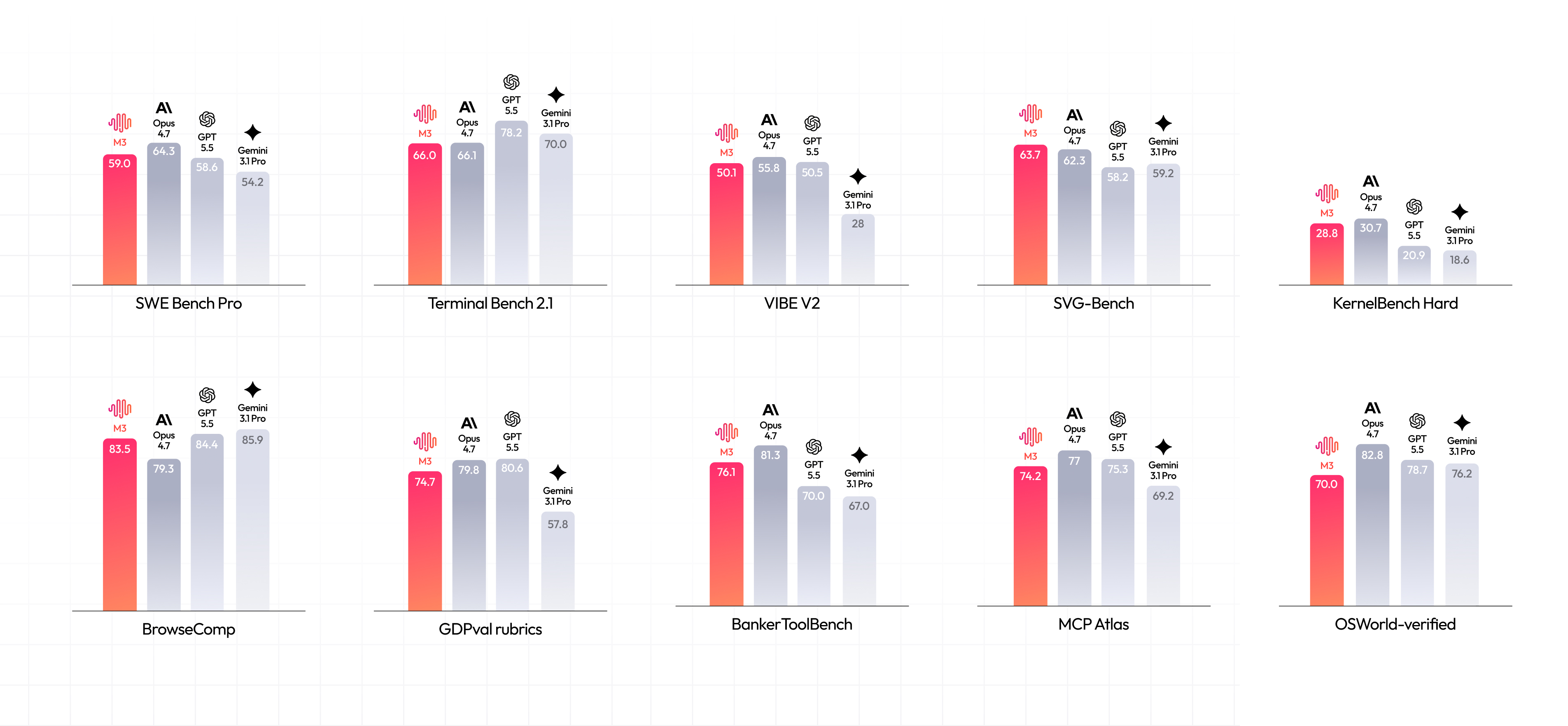
Why M3 Matters
The current generation of AI power users needs models that can do more than answer short prompts. Real workflows are messy: a coding agent needs to read many files, keep the task history in memory, inspect logs, revise patches, call tools, and recover from mistakes. A research assistant may need to hold long documents, compare sources, and reason across thousands of lines of context.
M3 is designed for exactly this kind of workload.
M3 is built around MSA, or MiniMax Sparse Attention, which is designed to make very long context more practical. MiniMax describes M3 as a coding and agentic frontier model with native multimodal capability and up to 1M tokens of context. That makes it especially interesting for developers who work with OpenCode, Cline, Cursor-like coding agents, terminal agents, browser agents, and custom AI automation tools.
Try M3 on TokenFans
M3 is now available on TokenFans through the same unified access experience you already use.
For TokenFans AI power users, M3 is a practical new candidate for daily use: not because every official benchmark should be accepted at face value, but because its design matches where advanced AI workflows are heading: longer context, more tools, more coding, and more agentic execution.
TokenFans makes it easier to test M3 alongside other models through one unified access layer. That means you can compare M3 in the places where model quality actually matters: your own codebase, your own prompts, your own agent setup, and your own latency and cost expectations.
If you already use TokenFans with OpenCode, Cline, or other AI developer tools, M3 is a strong model to add to your rotation. MiniMax M3 is now live on TokenFans. Try MiniMax M3 on TokenFans and see how it performs in your own stack.